Réaffecter des données pour une meilleure sécurité routière
SÉCURITÉ
La création d’ensembles de données faisant intervenir des acteurs publics et privés, les réseaux sociaux ainsi que des sources plus traditionnelles peut ouvrir la voie à des politiques et des investissements intelligents et bénéfiques sur le plan social.
Si la mortalité sur les routes était réduite de moitié (Objectif de développement durable 3.6), ce seraient 675 000 vies de sauvées chaque année. Pourtant, les investissements dans la réglementation, la mise en application des lois, l’éducation et les infrastructures qu’il faudrait réaliser à l’échelle nationale pour atteindre cette cible ambitieuse sont souvent hors de portée. Le manque de ressources exige des pays qu’ils décident avec discernement dans quels domaines investir et comment. Savoir où et quand se produisent les accidents de la route peut contribuer à déterminer où investir en priorité. Malheureusement, face à ces choix difficiles, de nombreux pays n’ont pas ou guère de données sur les accidents de la route et ne disposent pas de capacités suffisantes pour analyser les données à leur disposition, le cas échéant. Les données officielles sur les accidents de la route ne couvrent que 56 % des décès en moyenne dans les pays à faible revenu et à revenu intermédiaire1.
Certains accidents sont bel et bien signalés, mais ces signalements se noient dans la masse de paperasse ou les informations sont recueillies par des opérateurs privés au lieu d’être converties en données utiles ou communiquées aux personnes qui en ont besoin pour prendre des décisions sur les actions à mener. Au Kenya, où les chiffres officiels sur le nombre de décès sont 4,5 fois inférieurs à la réalité2, l’expansion rapide des téléphones portables et des réseaux sociaux offre l’occasion d’utiliser les signalements des navetteurs sur les conditions de circulation comme source de données potentielle sur les accidents de la route.
L’exploration des mégadonnées, combinée à la numérisation des signalements officiels sur papier, a démontré qu’il était possible d’utiliser des données disparates pour éclairer des analyses de l’espace urbain, l’aménagement et la gestion des villes3. Des chercheurs ont coopéré étroitement avec le Service de police national du Kenya pour numériser plus de 10 000 signalements effectués dans quatorze postes de police de Nairobi sur la période allant de 2013 à 2020, afin de créer le premier ensemble numérique de données administratives géolocalisées sur les accidents de la route dans la ville. Ils ont combiné des données administratives à des données recueillies de manière participative à l’aide d’une application logicielle pour appareils portables et d’une plateforme de service de messages courts (SMS) sur les conditions de circulation appelée Ma3Route, laquelle compte plus de 1,1 million d’utilisateurs inscrits au Kenya. Ils ont analysé 870 000 tweets liés à la circulation publiés entre 2012 et 2020, afin de recenser et de géolocaliser 36 428 signalements d’accidents de la route en créant et en améliorant des algorithmes de traitement automatique des langues et d’analyse géosémantique4.
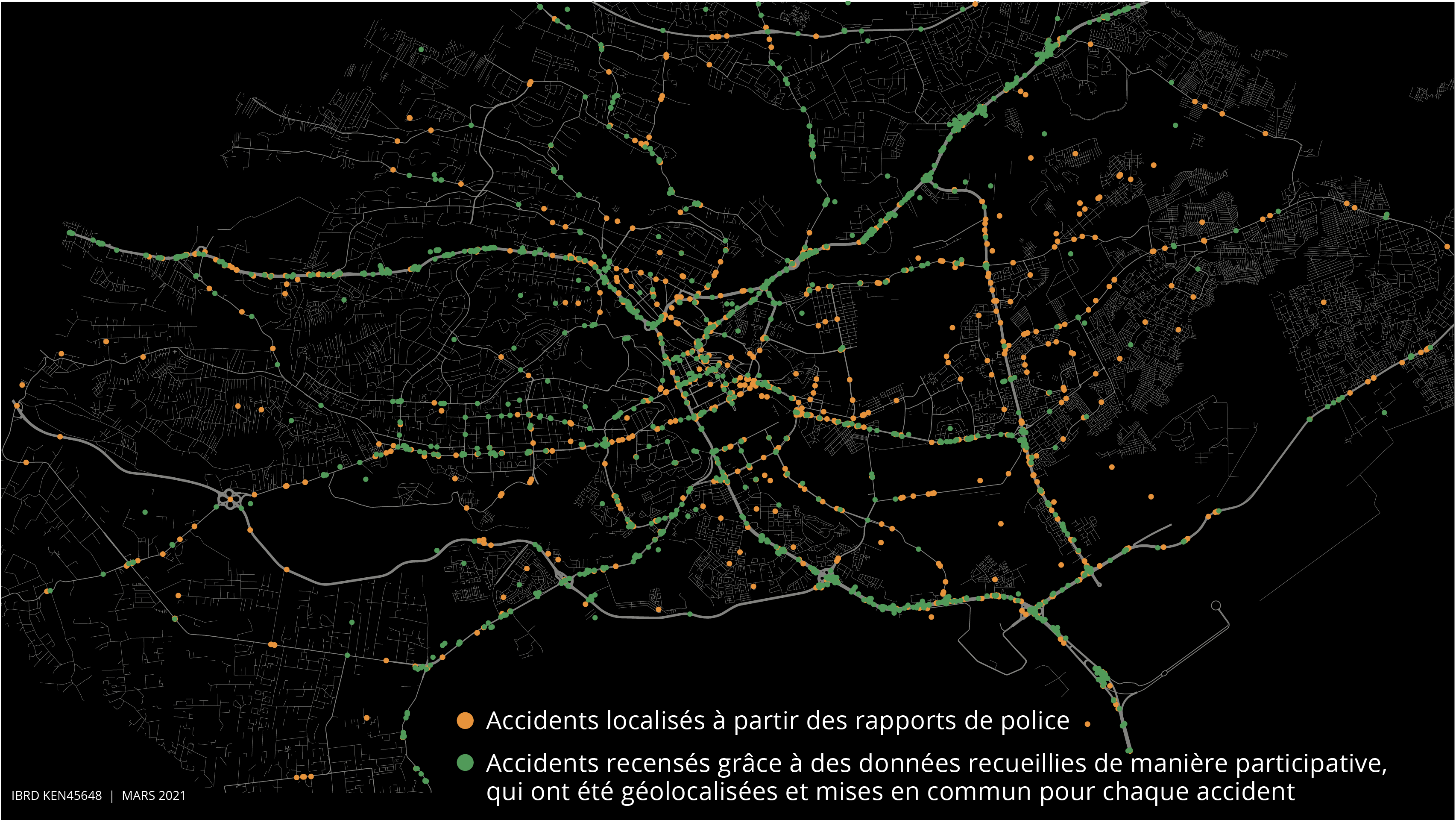
Source: Milusheva et al. 2020.
Note: Les données représentées sur la carte concernent la période allant de juillet 2017 à juillet 2018.
Pour vérifier l’exactitude des données recueillies de manière participative et l’efficacité des algorithmes, l’équipe a envoyé une entreprise de livraison à moto sur les lieux des accidents quelques minutes après leur signalement pour un sous-ensemble de signalements. Dans 92 % des cas, il s’est avéré que l’accident s’était bel et bien produit à l’endroit indiqué ou à proximité. En combinant ces sources de données, les chercheurs ont pu localiser les 5 % de routes (points noirs) où 50 % des accidents de la circulation mortels se produisaient dans la ville (carte S4.2.1).
Cet exercice a démontré qu’en s’attaquant à la rareté des données, on pouvait remédier à un problème qui semblait insoluble. Dans ce cas-ci, il est impossible d’investir dans la sécurité routière sur un réseau routier de 6 200 kilomètres de long. La numérisation et l’analyse de données administratives et de variables sur les personnes blessées et décédées peuvent aider à réduire la liste des lieux et des moments de la journée et de la semaine où les accidents les plus graves sont les plus probables. L’analyse offre une feuille de route inestimable pour les futures initiatives de réglementation, de développement des infrastructures et de mise en application des lois.
La question pourrait être explorée plus avant en intégrant les données existantes et en recueillant d’autres informations, telles que les données d’Uber et de Waze concernant la vitesse moyenne sur les différents tronçons et les obstacles présents sur la route, les données de Google Maps sur l’utilisation des terres, et les données météorologiques sur les conditions de conduite. Les chercheurs ont également investi dans une initiative de collecte massive de données visant à étudier les infrastructures et à enregistrer sur vidéo et coder le comportement des usagers de la route dans 200 zones considérées comme des points noirs de la ville pour ce qui est du nombre d’accidents de la route. L’analyse de ces nouvelles données permettra d’émettre des hypothèses afin d’optimiser la réaction des pouvoirs publics en matière de sécurité routière.
De manière générale, la création de jeux de données à partir de sources publiques et privées, de réseaux sociaux et de sources plus traditionnelles peut ouvrir la voie à des politiques et des investissements intelligents et bénéfiques sur le plan social.
- Calculs de l’équipe du Rapport sur le développement dans le monde 2021 et de l’Organisation mondiale de la santé (OMS) basés sur une comparaison des décès signalés repris dans le Rapport de situation sur la sécurité routière dans le monde de l’OMS (WHO 2018).
- WHO (2018).
- Milusheva et al. (2020).
- Les nouveaux algorithmes se fondent sur les travaux de Finkel, Grenager et Manning (2005) ; Gelernter et Balaji (2013) ; et Ritter et al. (2011).
- Finkel, Jenny Rose, Trond Grenager, and Christopher Manning. 2005. “Incorporating Non-local Information into Information Extraction Systems by Gibbs Sampling.” In 43rd Annual Meeting of the Association for Computational Linguistics: Proceedings of the Conference, edited by Kevin Knight, Hwee Tou Ng, and Kemal Oflazer, 363–70. New Brunswick, NJ: Association for Computational Linguistics.
- Gelernter, Judith, and Shilpa Balaji. 2013. “An Algorithm for Local Geoparsing of Microtext.” GeoInformatica 17 (4): 635–67.
- Milusheva, Sveta, Robert Marty, Guadalupe Bedoya, Elizabeth Resor, Sarah Williams, and Arianna Legovini. 2020. “Can Crowdsourcing Create the Missing Crash Data?” In COMPASS ’20: Proceedings of the 3rd ACM SIGCAS Conference on Computing and Sustainable Societies, 305–06. New York: Association for Computing Machinery.
- Ritter, Alan, Sam Clark, Mausam, and Oren Willi Etzioni. 2011. “Named Entity Recognition in Tweets: An Experimental Study.” In Conference on Empirical Methods in Natural Language Processing: Proceedings of the Conference, 1524–34. Stroudsburg, PA: Association for Computational Linguistics.
- WHO (World Health Organization). 2018. Global Status Report on Road Safety 2018. Geneva: WHO.